
在本文的上本部分中,我们探讨了数据中心电源容量设计及功率消耗等因素,接下来我们将为大家介绍系统的可靠性和可用性等概念。
市场调查机构IDC企业平台和数据中心趋势组的副总裁Michelle Bailey表示,是否更多的公司会决定出租它们的计算需求,这种趋势目前还不明确。她表示,“对它们来说,数据中心具有很长的生命周期,因此事情不会发生巨变。对许多客户来说,用好旧设备具有更长远的意义。”
能源只会越来越贵
的确,现在原油价格非常便宜,但是企业管理者脑海中依然不会忘记不久前每桶140美元的高价。
塔塔通信欧洲全球服务部门的管理服务主管Rhys Amarili表示,对能源价格再次暴涨的担心,使得很多公司考虑采取方式让自己的数据中心更高效。他的公司目前拥有近100万平房英尺空间的数据中心,而且还计划投资20多亿美元来扩展它们的容量,以满足客户数据需求。
Amarilli表示,“数据中心的确消耗大量的电能,我认为提高效率在人们日程表上已经是一件非常紧迫的事情。”
数据中心选址仍然非常重要
由于数据中心的能源需求,寻找一个理想的位置成为一个难题。在世界上很多地方能源基础设施已经负担过重,并非只有发展中国家面临这个问题。
来自IBM的Lechner表示,“在世界上某些地方——比如伦敦和纽约——已经根本不可能让其数据中心从当地电力网中获得更多电能,这不是一个环境问题;而是一个接入问题”
Lechner表示,这个问题同样影响当前数据设备:在最近的一个调查中,半数以上受访公司表示,在2008年由于电力或运营问题,数据中心遭遇了断电问题。
碳排放限制的担忧
尽管目前还没有排碳上限管制与交易制度(cap-and-trade),不过某些管理者预计迟早会推出该项政策。
塔塔通讯认为,欧洲和美国将在未来五年内推出排碳上限管制与交易制度。美国总统奥巴马已经在其2010年预算中提议了这样一个系统。
塔塔通讯数据中心服务副总裁Abid Qadiri表示,“所有人都在关注碳排放。”
IBM的调查验证了这一点。这个信息科技巨人发现,82%的管理者认为,气候变化立法将会在未来五年对他们产生影响。
企业希望具有绿色形象
即使没有碳排放征税,企业管理者也会因为公众关系价值而关注转型绿色企业。
IBM的Lechner表示,除了降低能源成本之外,倡导绿色技术的公司势必更容易赢得客户青睐。
在IBM的管理者调查中, 80%的CIO认为,具有一个绿色企业日程会对企业在市场中的成功产生积极影响。信息科技行业占据了全球2.5%的能源使用和二氧化碳排放,而且其增长速度比平均能源使用速度高12倍。
Lechner表示,“信息科技能源使用还有很大的空间可以改善。”
关于系统可靠性和可用性的讨论
就数据中心的统筹设计而言,必须讨论的另一个重要问题是系统的可用性和可靠性。很多客户、设计人员和设备提供商在谈到可用性时很少采用量化的概念,也很少了解实现这些目标须采取的措施。例如当前业界使用非常频繁的“99.999%”。“5个9”相当于每年5分钟的宕机时间。目标固然理想,但是要在很长时间内保持这一标准就必须满足一些实际要求,而这些要求却常常得不到设计者足够的重视。
对可用性的误解
一个常见的误解是可用性是在限定的时间间隔内测量出来的数据,而不是一个连续测量值。例如,如果数据中心一年未发生宕机,但在随后的1个月发生了1小时的断电。在这种情况下,如果说数据中心在除了该月之外的所有月份都达到了“5个9”的可用性,那么从技术角度来讲这是不准确的。实际上,1小时的断电会使数据中心的可用性在12年内达不到“5个9”的目标,其原因如图5所示。
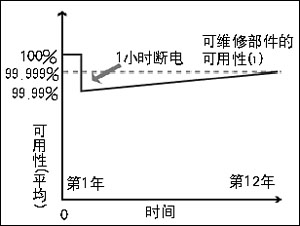
图5 1小时断电对可用性的影响
可用性是在系统运行寿命期内的连续测量值,它是用总的正常运行时间除以总的运行时间得出的。通过调整时间框架,尤其是缩短所计算的时间,系统可用性目标的实现变得相对容易一些。每个月签定的服务级别协议就是其中一个常见的实例。将可用性时间划分为1个月的时间间隔可以达到高级别的可用性目标,但是相对于真正的系统可用性而言则没有太大的意义。
在确定可用性目标时,人们很少为确定数据中心实际可能达到的潜在可用性目标而进行认真的分析。部分系统每年可能发生几十次一两秒钟的断电,1 分钟以下的中等程度的断电事故在一年内可能出现5~6次,1小时或更长时间的断电可能一两年才会出现1次。
在建立这样一个系统模型时,需要考虑频度和持续时间的事件密度函数。即使5秒钟的断电也可能会导致发电机启动,并影响不间断电源电池。从根本上来说,对一个复杂的电源系统来说,一个5分钟的事件与60个5秒钟的事件之间有着巨大的区别。
与此同时,还要考虑重新启动和恢复时间,一次1秒钟的断电可能会使服务器宕机20分钟。因此,考虑可用性时存在很多的统计属性和非线性关系,使得这种可用性计算变得非常困难。不考虑这些电源事件因素的模型得到的结果是没有意义的,甚至会导致错误的结论。
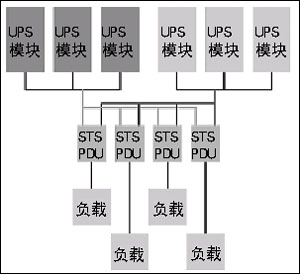
图6 典型的冗余策略
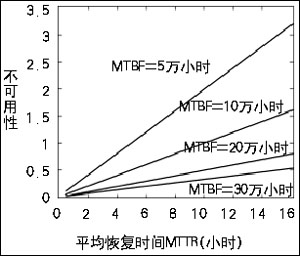
图7 系统MTTR值与不可用性(1-可用性)的关系曲线
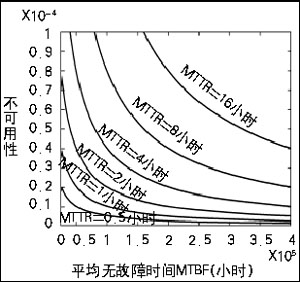
图8 系统MTBF值与不可用性的关系曲线
对冗余系统的正确评估
实现可用性的下一个步骤是评估电源系统的冗余和可维护性策略。常用的冗余形式各异,但常常缺少优化的方法。图8 显示的就是这样的实例。
如图6所示,UPS系统采用了全面的系统冗余(2N),但是单电源负载是由一个PDU供电的。而这个PDU又串联了很多组件,成为单路径故障点。其中包括系统输入断路器、变压器、输出断路器、主配电盘断路器,以及支路断路器。在某些设计中可能形成5~7个单路径故障点。
这种设计使UPS系统有充足的冗余,但是在配电系统中却没有。这样一来,会导致可用性瓶颈,或一部分可用性较高,而另一部分可用性较低。假定宕机时间是可累加的,可用性不高的环节始终会妨碍系统达到最优的可用性,这在统筹设计过程中是一个需要特别考虑的重要因素。一个系统内部的可用性差异意味着,如果在一个地方花费过多的资金,其他地方的投入将减少。实现平衡对于最大限度利用资金获得最佳的可用性来说至关重要。
MTTR对可用性的特殊作用
优化可用性的另一个方面与恢复时间有关。可用性是与平均无故障工作时间(MTBF)、平均恢复时间(MTTR)相关联的函数。所有的系统都会在某个点上出现故障。这是事实,但是,可用性高的系统不会受到太大影响,并且可以快速、高效地修复。有证据显示,如果MTTR过长,就不可能达到较高的可用性。
从图7和图8可以看出,平均恢复时间对提高系统可用性的作用远大于平均故障时间(MTRF)的作用,其原因有以下几点:
第一,MTTR对提高可用性的作用是MTBF根本达不到的。
第二,提高MTBF值对可用性的提高并不是总有效的。
第三,MTTR的变化与可用性总是呈线性关系。
另一个需要了解的影响可用性的情况是,数据中心的操作人员无法控制一个部件的MTBF,但是在很大程度上,MTTR是可以控制的。数据中心操作人员可以控制MTTR,这就要求现场必须储存100%的备件,操作人员需要接受有关设备操作的培训,同时要了解必要时更换或维修设备的程序。
考虑备件库存是建立数据中心可用性预期的一个重要组成部分。为此,应对本地人员进行培训,详细讲解操作程序。与涉及关键业务设施的其他领域相比,数据中心的操作人员接受的培训少,操作程序亦很简单。此外,复杂性也是造成宕机的重要原因。有最近的统计数据显示,高达50%的宕机与人为错误有关。很明显,必不可少的培训和备件是实现高可用性的先决条件。
EPO对可用性的影响
可用性数据是建立在统计学或经验数据的基础上。而这些统计或经验数据又都是基于以前的运行经验。
其中有一个原则是关于数据中心紧急断电(EPO)开关的使用。在大部分情况下,EPO系统是必备的,而且它们被设计成数据中心必不可少的重要环节。出于安全原因,它们能够立即使数据中心完全宕机,但在其设计方面也常有不足之处。鉴于它们对数据中心的影响,必须详尽地考虑这些因素,仔细检查隐藏的陷阱。
第二个原则被认为是提高可用性的关键原则。该原则指出,高可用性系统要在系统出现故障时使系统的状态变化最小化。某些系统设计时尽管提供了冗余措施,但如果一个部件发生故障,仍然需要进行状态的多种变更。换句话说,如果出现故障,最好不要改变状态,也不要重新确定电源路径,或者被迫启动系统;而且此时替代系统已经可以运行,且准备就绪。这样的系统冗余最可靠,但也会更昂贵。
综上所述,在建立完全适合客户需要的系统过程中,需要统筹考虑以下各种因素:
- 当前的系统需求
- 后期未来的系统需求
- 系统可用性要求
- 资金预算状况
- 商业模型
认真地检查所有这些因素,会使客户满意度达到最高水平,并使项目和业务的成功概率达到最大。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
看IBM数据科学团队如何助力企业用户AI项目
在下面的Q&A中,IBM公司的Seth Dobrin探讨了如何提高企业用户对机器学习和AI项目的兴趣, […]
-
DR基础知识:灾难恢复计划和灾难恢复策略
IT灾难恢复(DR)计划的主要目标是制定详细的恢复计划,以在意外中断时执行。 这种计划应该列明详细步骤,说明在 […]
-
为超融合架构选择合适的数据中心冷却系统
超融合基础架构会给新的数据中心冷却方面带来一些新的挑战,在选择和实施之前,我们来看看哪些温度和冷却单元的效率是最好的……
-
IDC Directions 2017:值得期待的智能数据中心技术
智能技术能够让数据中心变得更为自动化、简单,不过企业需要为其实施做好准备,了解如何从旧的设备平稳过渡至智能的数据中心。